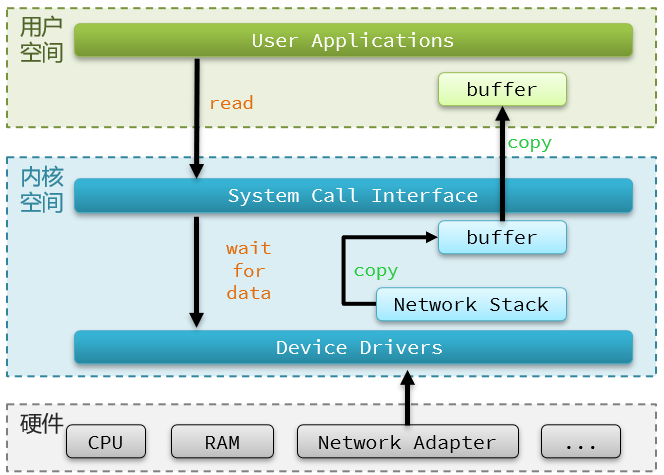
用户空间和内核态空间
用户的应用,比如redis,mysql等是没有办法去执行访问我们操作系统的硬件的,所以我们可以通过发行版(例如乌班图、CentOS等)的这个壳子去访问内核,再通过内核去访问计算机硬件
计算机硬件包括,如cpu,内存,网卡等等,内核(通过寻址空间)可以操作硬件,但是内核需要不同设备的驱动,有了这些驱动之后,内核就可以去对计算机硬件去进行内存管理,文件系统的管理,进程的管理等等

想要用户的应用来访问,计算机就必须要通过对外暴露的一些接口才能访问到,从而简洁地实现对内核的操控,但是内核本身上来说也是一个应用,所以本身也需要一些内存,cpu等设备资源,用户应用本身也在消耗这些资源,如果不加任何限制,用户去操作随意的去操作我们的资源,就可能导致一些冲突,甚至有可能导致我们的系统出现无法运行的问题,因此我们需要把用户和内核隔离开
寻址空间
进程的寻址空间划分成两部分:内核空间、用户空间
什么是寻址空间呢?我们的应用程序也好,还是内核空间也好,都是没有办法直接去物理内存的,而是通过分配一些虚拟内存映射到物理内存中,我们的内核和应用程序去访问虚拟内存的时候,就需要一个虚拟地址,这个地址是一个无符号的整数,比如一个32位的操作系统,他的带宽就是32,他的虚拟地址就是2的32次方,也就是说他寻址的范围就是0~2的32次方, 这片寻址空间对应的就是2的32个字节,就是4GB,这个4GB,会有3个GB分给用户空间,会有1GB给内核系统

在linux中,命令的权限分成两个等级,0和3
- 用户空间只能执行受限的命令(Ring3),而且不能直接调用系统资源,必须通过内核提供的接口来访问
- 内核空间可以执行特权命令(Ring0),调用一切系统资源
所以一般情况下,用户的操作是运行在用户空间,而内核运行的数据是在内核空间的,而有的情况下,一个应用程序需要去调用一些特权资源,去调用一些内核空间的操作,所以此时它们需要在用户态和内核态之间进行切换。
比如:
Linux系统为了提高IO效率,会在用户空间和内核空间都加入缓冲区:
- 写数据时,要把用户缓冲数据拷贝到内核缓冲区,然后写入设备
- 读数据时,要从设备读取数据到内核缓冲区,然后拷贝到用户缓冲区
针对这个操作:我们的用户在写读数据时,会向内核态申请,想要读取内核的数据,而内核数据要去等待驱动程序从硬件上读取数据,当从磁盘上加载到数据之后,内核会将数据写入到内核的缓冲区中,然后再将数据拷贝到用户态的buffer中,然后再返回给应用程序,整体而言,速度慢就是这个原因,为了加速,我们希望read也好,还是wait for data也好,最好都不要等待,或者时间尽量的短。
网络模型
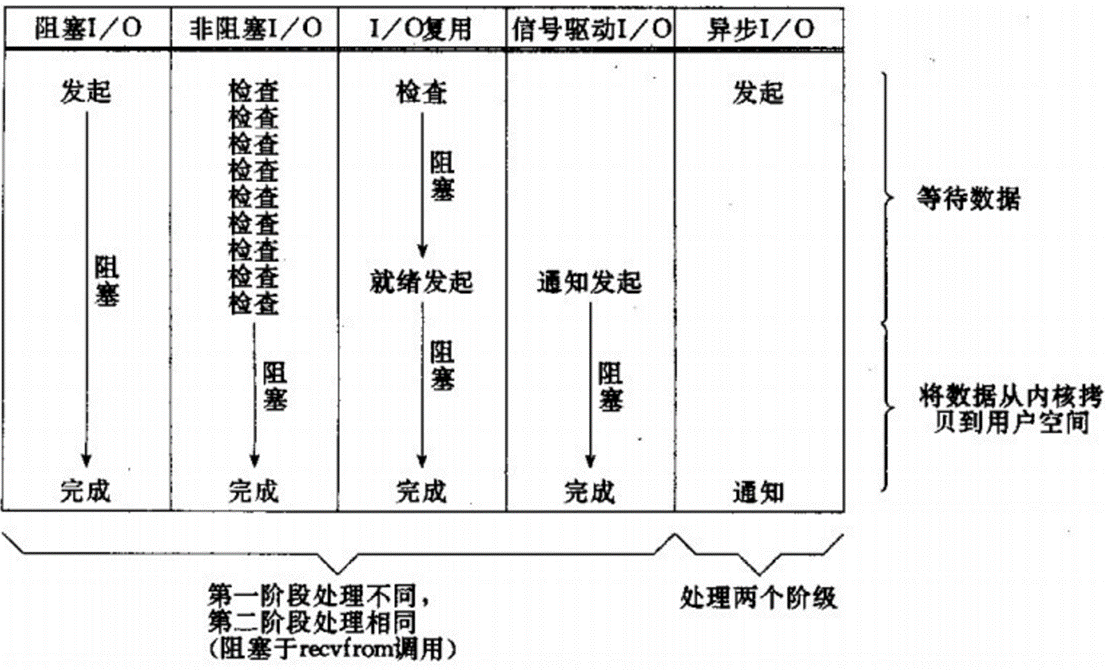
先回顾一下操作系统的一次IO流程:(用户不能直接读取硬件中的内容)
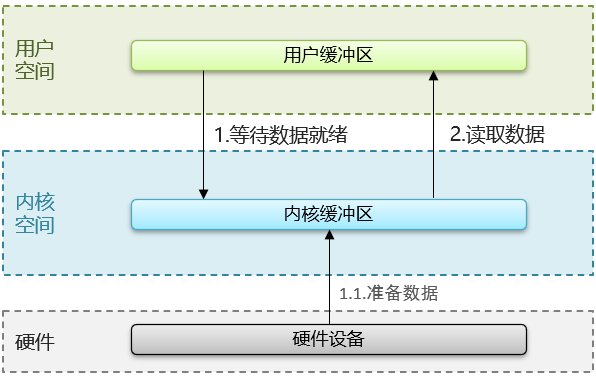
不同IO模型的差别也就是体现在1、2阶段上
BIO (Blocking I/O)
同步阻塞
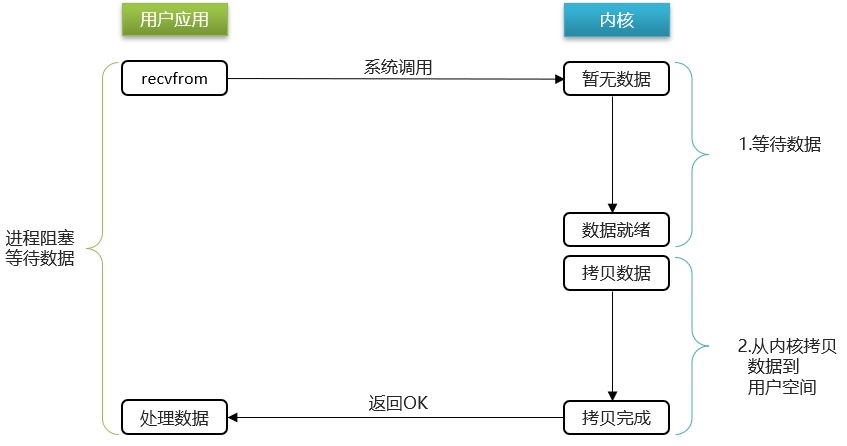
阻塞IO模型中,用户进程在两个阶段都是阻塞状态。
NIO (Non-blocking/New I/O)
同步非阻塞
提出:解决BIO在高并发场景下产生的问题。
将第一阶段改为非阻塞,客户端只需不断询问数据就绪状态,无需一直阻塞等待

由于需要不断盲轮询且在数据拷贝时仍然阻塞,NIO并未改善BIO性能问题。但这并不意味着NIO是无用的,在某些场景下只能使用NIO而且NIO是最优解,比如IO多路复用。
IO多路复用
无论是阻塞IO还是非阻塞IO,用户应用在一阶段都需要调用recvfrom来获取数据,差别在于无数据时的处理方案:
- 如果调用recvfrom时,恰好没有数据,阻塞IO会使CPU阻塞,非阻塞IO使CPU空转,都不能充分发挥CPU的作用。
- 如果调用recvfrom时,恰好有数据,则用户进程可以直接进入第二阶段,读取并处理数据
为了解决NIO的无意义的客户端连接遍历问题和BIO的用户进程阻塞问题,提出了IO多路复用的概念。
文件描述符(File Descriptor):简称FD,是一个从0 开始的无符号整数,用来关联Linux中的一个文件。在Linux中,一切皆文件,例如常规文件、视频、硬件设备等,当然也包括网络套接字(Socket)。
IO多路复用:是利用单个线程来同时监听多个FD,并在某个FD可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。

阶段1:
- 用户进程调用select,指定要监听的FD集合
- 内核监听FD对应的多个socket
- 任意一个或多个socket数据就绪则返回readable
- 此过程中用户进程阻塞
阶段2:
- 用户进程找到就绪的socket
- 依次调用recvfrom读取数据
- 内核将数据拷贝到用户空间
- 用户进程处理数据
监听FD的方式
select和poll只会通知用户进程有FD就绪,但不确定具体是哪个FD,需要用户进程逐个遍历FD来确认 epoll则会在通知用户进程FD就绪的同时,把已就绪的FD写入用户空间
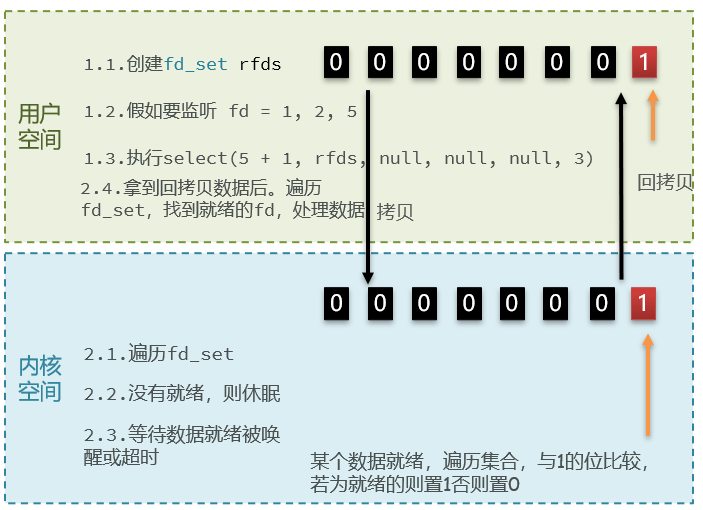
select
- 初始化fd_set,用于记录要监听的fd集合并记录其状态
- 将要监听的比特位置为1,从右侧开始计数

- 调用select函数,拷贝fd_set数组
- 内核监听并返回就绪fd数组

- 用户空间拿到后,遍历找出就绪的fd
// 定义类型别名 __fd_mask,本质是 long int
typedef long int __fd_mask;
/* fd_set 记录要监听的fd集合,及其对应状态 */
typedef struct {
// fds_bits是long类型数组,长度为 1024/32 = 32
// 共1024个bit位,每个bit位代表一个fd,0代表未就绪,1代表就绪
__fd_mask fds_bits[__FD_SETSIZE / __NFDBITS];
// ...
} fd_set;
// select函数,用于监听fd_set,也就是多个fd的集合
int select(
int nfds, // 要监视的fd_set的最大fd + 1
fd_set *readfds, // 要监听读事件的fd集合
fd_set *writefds,// 要监听写事件的fd集合
fd_set *exceptfds, // // 要监听异常事件的fd集合
// 超时时间,null-用不超时;0-不阻塞等待;大于0-固定等待时间
struct timeval *timeout
);
select模式存在的问题:
- 需要将整个fd_set从用户空间拷贝到内核空间,select结束还要再次拷贝回用户空间
- select无法得知具体是哪个fd就绪,需要遍历整个fd_set
- fd_set监听的fd数量不能超过1024(32 X 32)
poll
poll模式对select模式做了简单改进,但性能提升不明显
- 创建pollfd数组,向其中添加关注的fd信息,数组大小自定义
- 调用poll函数,将pollfd数组拷贝到内核空间,转链表存储,无上限
- 内核遍历fd,判断是否就绪
- 数据就绪或超时后,拷贝pollfd数组到用户空间,返回就绪fd数量n
- 用户进程判断n是否大于0
- 大于0则遍历pollfd数组,找到就绪的fd
// pollfd 中的事件类型
#define POLLIN //可读事件
#define POLLOUT //可写事件
#define POLLERR //错误事件
#define POLLNVAL //fd未打开
// pollfd结构
struct pollfd {
int fd; /* 要监听的fd */
short int events; /* 要监听的事件类型:读、写、异常 */
short int revents;/* 实际发生的事件类型 */
};
// poll函数
int poll(
struct pollfd *fds, // pollfd数组,可以自定义大小
nfds_t nfds, // 数组元素个数
int timeout // 超时时间
);
与select对比:
- select模式中的fd_set大小固定为1024,而pollfd在内核中采用链表,理论上无上限
- 监听FD越多,每次遍历消耗时间也越久,性能反而会下降
epoll
- 创建一个epoll实例,内部是event poll,返回对应的句柄epfd
- 将一个FD添加到epoll的红黑树中,并设置ep_poll_callback,callback触发时,就把对应的FD加入到rdlist这个就绪列表中
- 检查rdlist列表是否为空,不为空则返回就绪的FD的数量
struct eventpoll {
//...
struct rb_root rbr; // 一颗红黑树,记录要监听的FD
struct list_head rdlist;// 一个链表,记录就绪的FD
//...
};
// 1.创建一个epoll实例,内部是event poll,返回对应的句柄epfd
int epoll_create(int size);
// 2.将一个FD添加到epoll的红黑树中,并设置ep_poll_callback
// callback触发时,就把对应的FD加入到rdlist这个就绪列表中
int epoll_ctl(
int epfd, // epoll实例的句柄
int op, // 要执行的操作,包括:ADD、MOD、DEL
int fd, // 要监听的FD
struct epoll_event *event // 要监听的事件类型:读、写、异常等
);
// 3.检查rdlist列表是否为空,不为空则返回就绪的FD的数量
int epoll_wait(
int epfd, // epoll实例的句柄
struct epoll_event *events, // 空event数组,用于接收就绪的FD
int maxevents, // events数组的最大长度
int timeout // 超时时间,-1永不超时;0不阻塞;大于0为阻塞时间
);
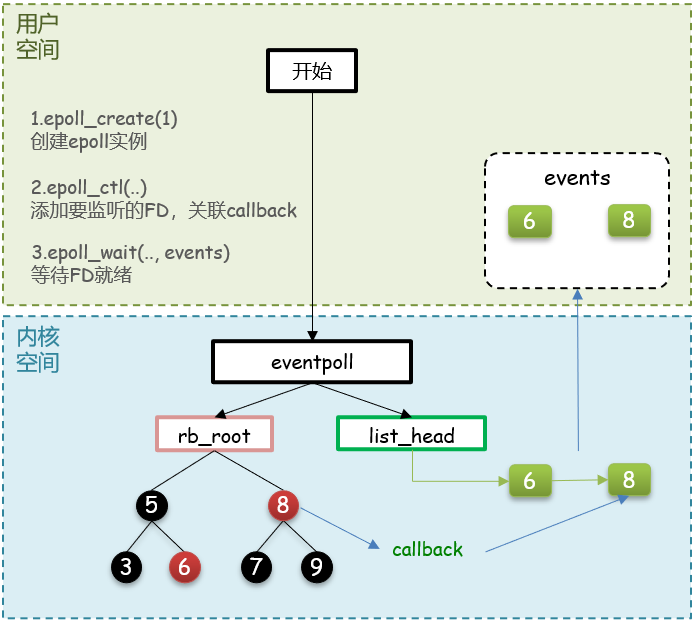
- 基于epoll实例中的红黑树保存要监听的FD,理论上无上限,而且增删改查效率都非常高
- 每个FD只需要执行一次epoll_ctl添加到红黑树,以后每次epol_wait无需传递任何参数,无需重复拷贝FD到内核空间
- 利用ep_poll_callback机制来监听FD状态,无需遍历所有FD,因此性能不会随监听的FD数量增多而下降
事件通知机制
当FD有数据可读时,我们调用epoll_wait(或者select、poll)可以得到通知。但是事件通知的模式有两种:
- LevelTriggered:简称LT,也叫做水平触发。只要某个FD中有数据可读,每次调用epoll_wait都会得到通知。若原链表中还有FD数据未读取完,会再次添加到链表。
- EdgeTriggered:简称ET,也叫做边沿触发。只有在某个FD有状态变化时,调用epoll_wait才会被通知。当FD从链表中移除后,不管是否读取完毕都不再添加回链表。
select和poll仅支持LT模式,epoll可以自由选择LT和ET两种模式
ET模式避免了LT模式可能出现的惊群现象(多个进程同时监听一个fd,且都在调用epoll_wait()函数,当使用LT进行二次回传时,所有进程都会被通知)
ET最好结合非阻塞IO读取数据。
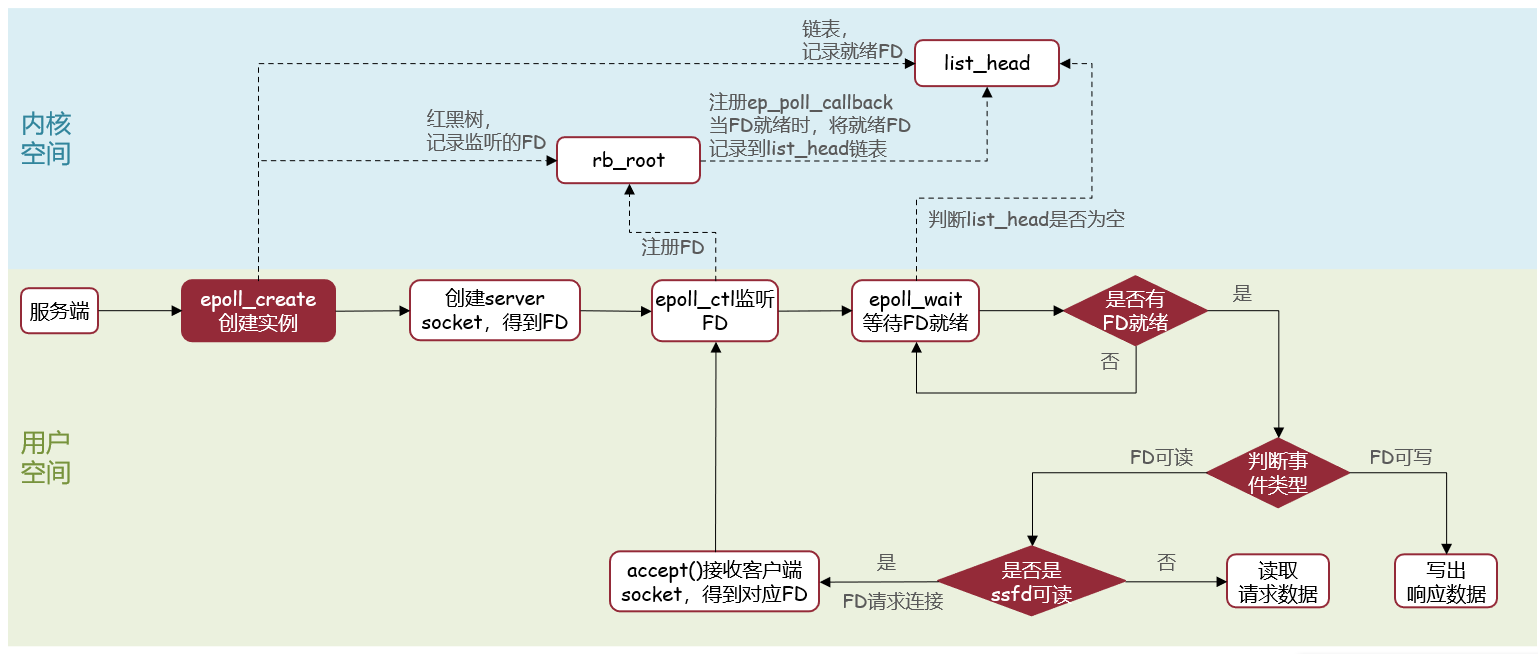
web服务流程
基于epoll模式实现的web服务:
信号驱动IO
信号驱动IO是与内核建立SIGIO的信号关联并设置回调,当内核有FD就绪时,会发出SIGIO信号通知用户,期间用户应用可以执行其它业务,无需阻塞等待。
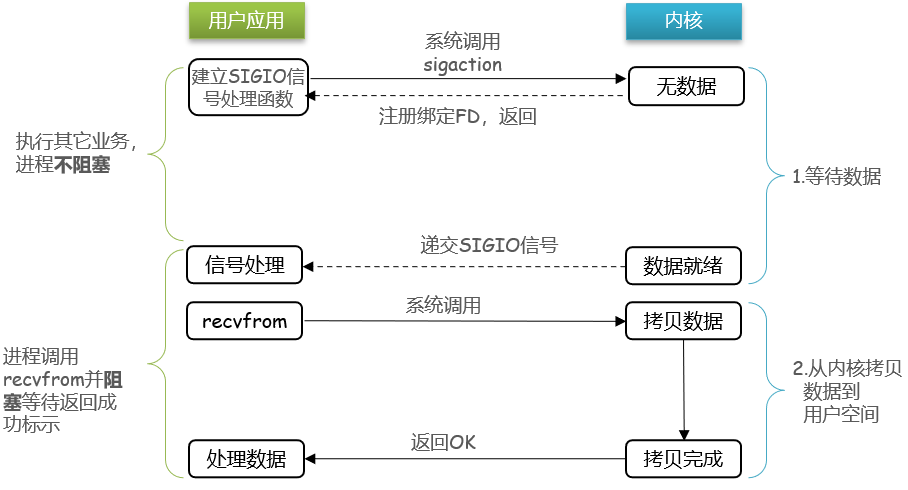
当有大量IO操作时,信号较多,SIGIO处理函数不能及时处理可能导致信号队列溢出,而且内核空间与用户空间的频繁信号交互性能也较低。
AIO (Asynchronous I/O)
异步非阻塞IO模型
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台线程异步处理完成,操作系统会通知相应的线程进行后续的操作。
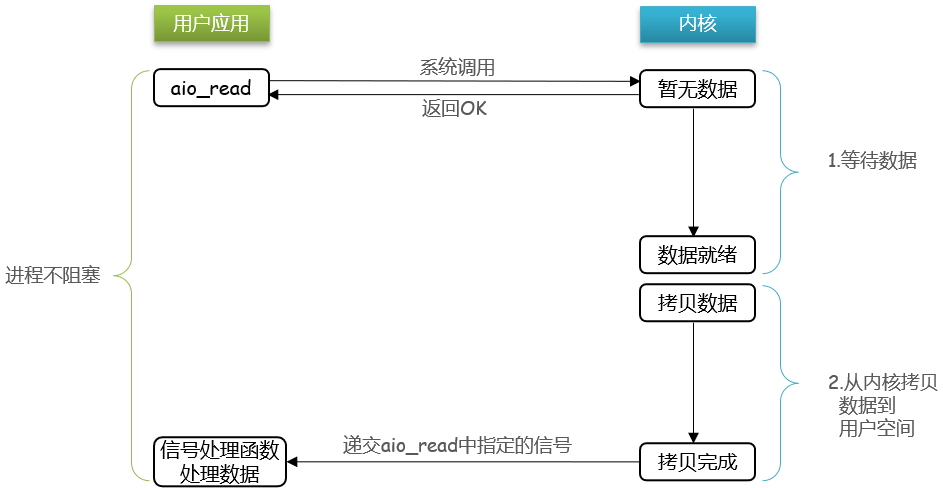
内核容易积累IO任务,高并发下容易造成系统崩溃。
小结
IO操作是同步还是异步,关键看数据在内核空间与用户空间的拷贝过程(数据读写的IO操作),也就是阶段二是同步还是异步
Redis网络模型
Redis到底是单线程还是多线程?
- 如果仅仅聊Redis的核心业务部分(命令处理),答案是单线程
- 如果是聊整个Redis,那么答案就是多线程
在Redis版本迭代过程中,在两个重要的时间节点上引入了多线程的支持:
- Redis v4.0:引入多线程异步处理一些耗时较旧的任务,例如异步删除命令unlink
- Redis v6.0:在核心网络模型中引入 多线程,进一步提高对于多核CPU的利用率
因此,对于Redis的核心网络模型,在Redis 6.0之前确实都是单线程。是利用epoll(Linux系统)这样的IO多路复用技术在事件循环中不断处理客户端情况。
为什么Redis要选择单线程?
- 抛开持久化不谈,Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度,因此多线程并不会带来巨大的性能提升。
- 多线程会导致过多的上下文切换,带来不必要的开销
- 引入多线程会面临线程安全问题,必然要引入线程锁这样的安全手段,实现复杂度增高,而且性能也会大打折扣
Redis单线程和多线程网络模型变更
Redis通过IO多路复用来提高网络性能,并且支持各种不同的多路复用实现,并且将这些实现进行封装, 提供了统一的高性能事件库API库 AE:
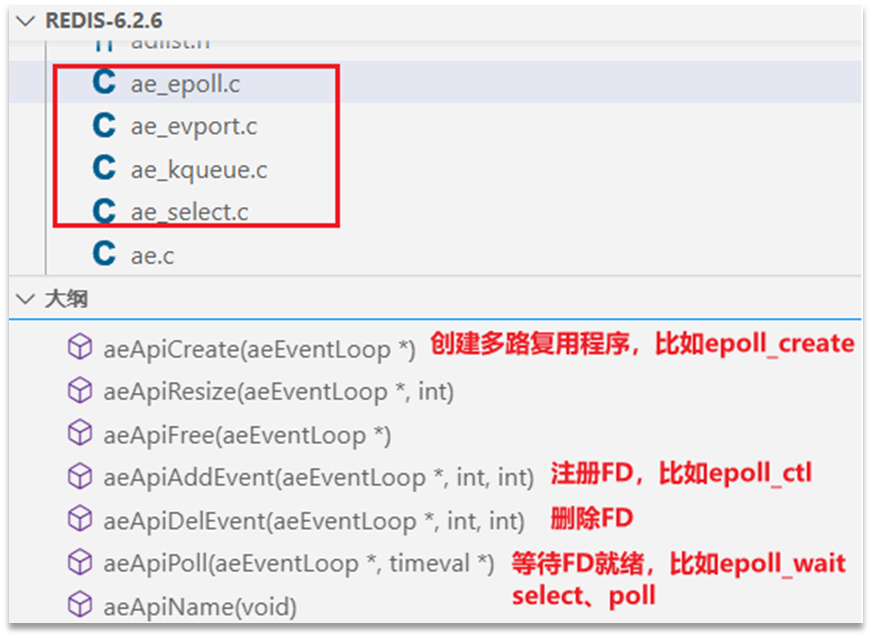
Redis默认采用epoll实现,当然也提供了select和kqueue实现。
从源码来看看Redis单线程网络模型的整个流程:
int main(
int argc,
char **argv
) {
// ...
// 初始化服务
initServer();
// ...
// 开始监听事件循环
aeMain(server.el);
// ...
}
void initServer(void) {
// ...
// 内部会调用 aeApiCreate(eventLoop),类似epoll_create
server.el = aeCreateEventLoop(
server.maxclients+CONFIG_FDSET_INCR);
// ...
// 监听TCP端口,创建ServerSocket,并得到FD
listenToPort(server.port,&server.ipfd)
// ...
// 注册 连接处理器,内部会调用 aeApiCreate(&server.ipfd)监听FD
createSocketAcceptHandler(&server.ipfd, acceptTcpHandler)
// 注册 ae_api_poll 前的处理器
aeSetBeforeSleepProc(server.el,beforeSleep);
}
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
// 循环监听事件
while (!eventLoop->stop) {
aeProcessEvents(
eventLoop,
AE_ALL_EVENTS|
AE_CALL_BEFORE_SLEEP|
AE_CALL_AFTER_SLEEP);
}
}
// 数据读处理器
void acceptTcpHandler(...) {
// ...
// 接收socket连接,获取FD
fd = accept(s,sa,len);
// ...
// 创建connection,关联fd
connection *conn = connCreateSocket();
conn.fd = fd;
// ...
// 内部调用aeApiAddEvent(fd,READABLE),
// 监听socket的FD读事件,并绑定读处理器readQueryFromClient
connSetReadHandler(conn, readQueryFromClient);
}
int aeProcessEvents(
aeEventLoop *eventLoop,
int flags ){
// ... 调用前置处理器 beforeSleep
eventLoop->beforesleep(eventLoop);
// 等待FD就绪,类似epoll_wait
numevents = aeApiPoll(eventLoop, tvp);
for (j = 0; j < numevents; j++) {
// 遍历处理就绪的FD,调用对应的处理器
}
}
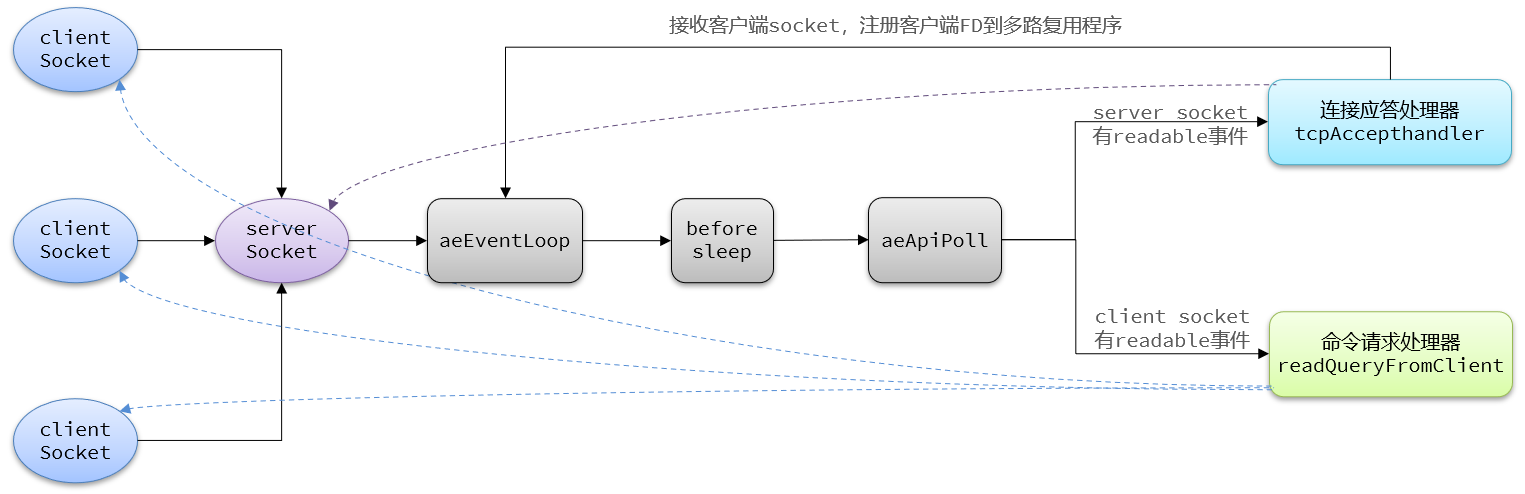
以上可以概括为下面这幅图:
void readQueryFromClient(connection *conn) {
// 获取当前客户端,客户端中有缓冲区用来读和写
client *c = connGetPrivateData(conn);
// 获取c->querybuf缓冲区大小
long int qblen = sdslen(c->querybuf);
// 读取请求数据到 c->querybuf 缓冲区
connRead(c->conn, c->querybuf+qblen, readlen);
// ...
// 解析缓冲区字符串,转为Redis命令参数存入 c->argv 数组
processInputBuffer(c);
// ...
// 处理 c->argv 中的命令
processCommand(c);
}
int processCommand(client *c) {
// ...
// 根据命令名称,寻找命令对应的command,例如 setCommand
c->cmd = c->lastcmd = lookupCommand(c->argv[0]->ptr);
// ...
// 执行command,得到响应结果,例如ping命令,对应pingCommand
c->cmd->proc(c);
// 把执行结果写出,例如ping命令,就返回"pong"给client,
// shared.pong是 字符串"pong"的SDS对象
addReply(c,shared.pong);
}
void addReply(client *c, robj *obj) {
// 尝试把结果写到 c-buf 客户端写缓存区
if (_addReplyToBuffer(c,obj->ptr,sdslen(obj->ptr)) != C_OK)
// 如果c->buf写不下,则写到 c->reply,这是一个链表,容量无上限
_addReplyProtoToList(c,obj->ptr,sdslen(obj->ptr));
// 将客户端添加到server.clients_pending_write这个队列,等待被写出
listAddNodeHead(server.clients_pending_write,c);
}
void beforeSleep(struct aeEventLoop *eventLoop){
// ...
// 定义迭代器,指向server.clients_pending_write->head;
listIter li;
li->next = server.clients_pending_write->head;
li->direction = AL_START_HEAD;
// 循环遍历待写出的client
while ((ln = listNext(&li))) {
// 内部调用aeApiAddEvent(fd,WRITEABLE),监听socket的FD读事件
// 并且绑定 写处理器 sendReplyToClient,可以把响应写到客户端socket
connSetWriteHandlerWithBarrier(c->conn, sendReplyToClient, ae_barrier)
}
}
- 当我们的客户端想要去连接我们服务器,会去到IO多路复用模型去排队等待派发
- 连接应答处理器接受读请求,然后把读请求注册到具体模型(各种处理器,如:acceptTcpHandler)中去
- 此时这些建立起来的连接,如果是客户端请求处理器去进行执行命令时,他会把数据读取出来,然后把数据放入到client中, clinet去解析当前的命令转化为redis认识的命令,接下来就开始处理这些命令,从redis中的command中找到这些命令,然后就真正的去操作对应的数据了
- 当数据操作完成后,会找到命令回复处理器,再由他将数据写出
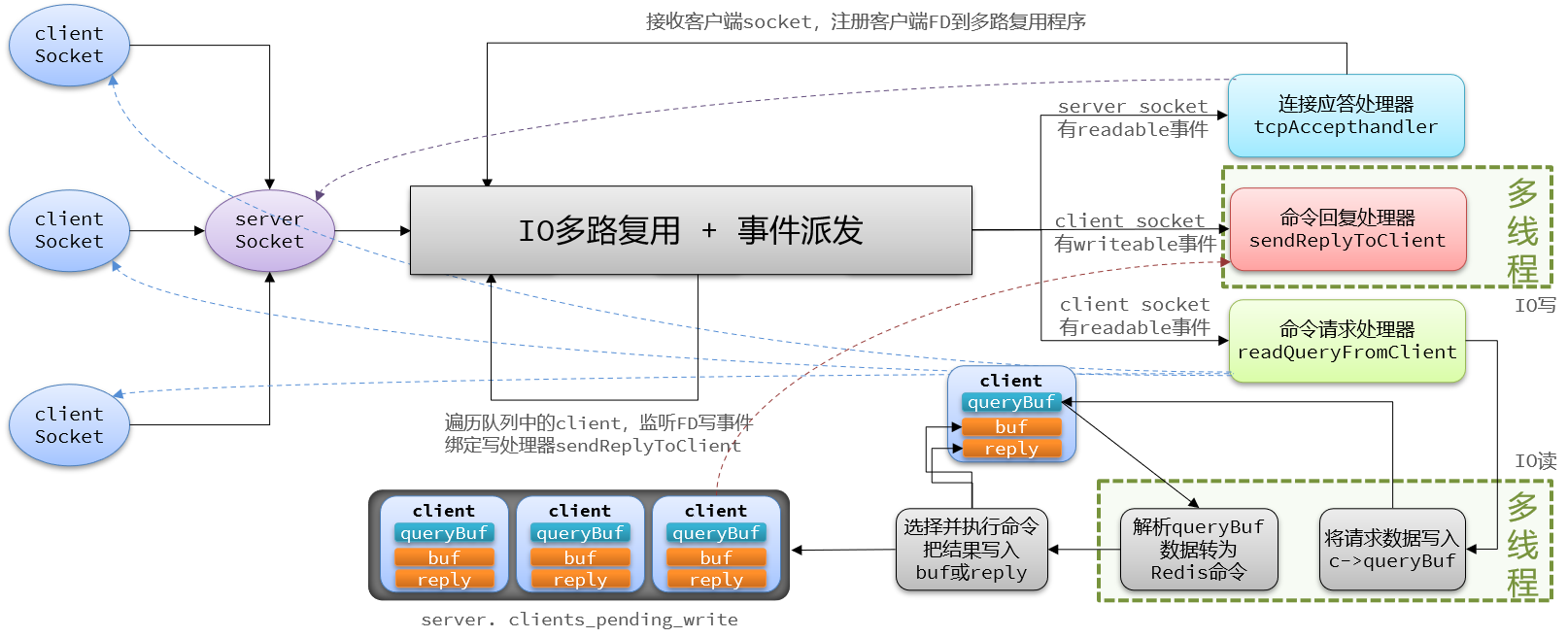
限制Redis性能的瓶颈永远不是基于内存的处理部分,而是网络IO带来的延时,所以在6.0版本之后,Redis优化了网络IO部分,也就是图中绿色框部分,这两部分的IO读写改为使用多线程实现后,Redis的性能得到了进一步的提升。
Comments NOTHING