谈及服务器端的负载均衡策略,首先想到的就是使用哈希算法,但是如果可用结点的数量发生变化,也就是在系统发生扩容或者收缩时,基本的哈希算法就无法满足我们的需求。
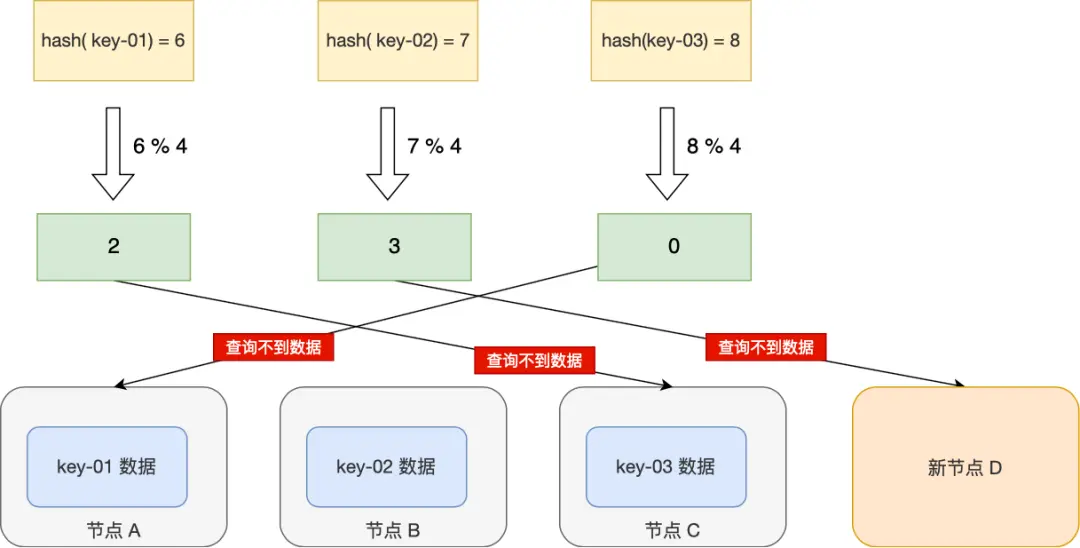
在上面提到的场景下,若对全部数据做数据迁移,这样的成本是巨大的,于是,一致性哈希算法的提出就完美解决了这个问题。
一致性哈希与普通哈希算法不同的是,一致性哈希始终是对 2 的 32 次方做取模运算,该值不随节点数量改变。

一致性哈希分为两步:
- 对存储结点做哈希运算
- 对数据进行存储或访问时,对数据做哈希映射
那么,若要对数据进行哈希映射得到一个结果要怎么找到存储数据的节点呢?
映射的结果往往在当前映射值向前找到的第一个结点,如下图所示:
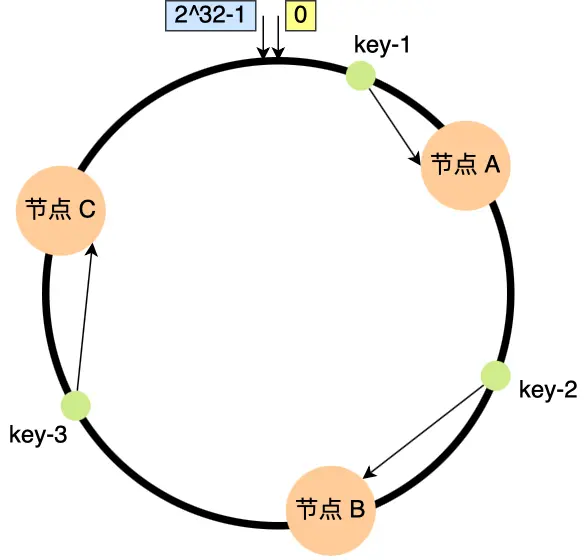
我们来看看如果发生节点数量改变会不会存在普通哈希算法的数据迁移问题,假设当前节点 A 宕机,针对 Key-1,其数据存放位置由原本的节点 A 变为了节点 B,其他数据存放位置不变。
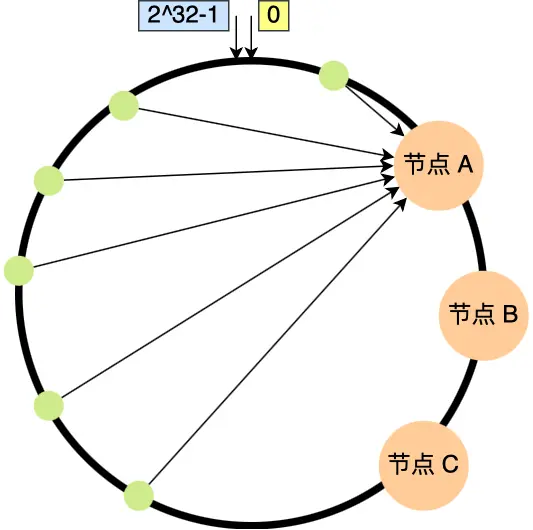
一致性哈希并不保证数据分布的均匀性,如下图所示,由于哈希特性,大量的数据被存放到了节点 A 上,若此时节点 A 发生宕机,数据的迁移成本也是很大的:
在实际运行中,通常会采用虚拟节点来解决数据平衡的问题,不再将真实节点映射到环上,而是将虚拟节点映射到环上:
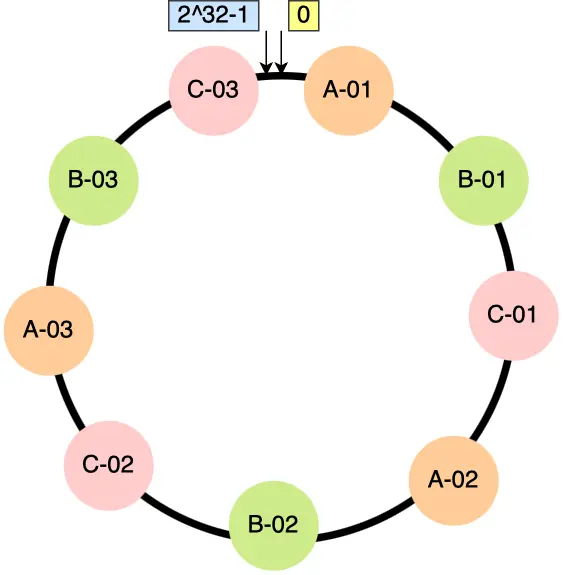
虚拟节点也提高了系统的稳定性,当发生节点数量减少时,相关的虚拟节点会共同分担系统变化。
Comments NOTHING