第一部分 数据系统基础
第一章 可靠、可拓展与可维护的应用系统
在当今的互联网系统中,应用可以大致分为以下两类:
- 数据密集型(Data-intensive)
- 计算密集型(Compute-intensive)
对于前者而言,其性能瓶颈往往是在数据量、数据的复杂度和数据的快速多边性。
数据密集型系统通常由以下几部分组成:数据库、高速缓存、索引、流式处理(持续将消息发送至另一个进程,处理采用异步方式)、批处理。
近年来出现的各种数据存储和处理的新工具,如Kafka、Redis等,逐渐将以上提到的数据系统从它们原来的传统定义中解放出来,系统之间的边界正在变得模糊。其主要原因是单个组件无法满足所有数据存储和处理的需求,将任务分解后,每个组件单独负责高效完成其中的一部分,多个组件之间通过应用层代码有机衔接起来。如下图所示:
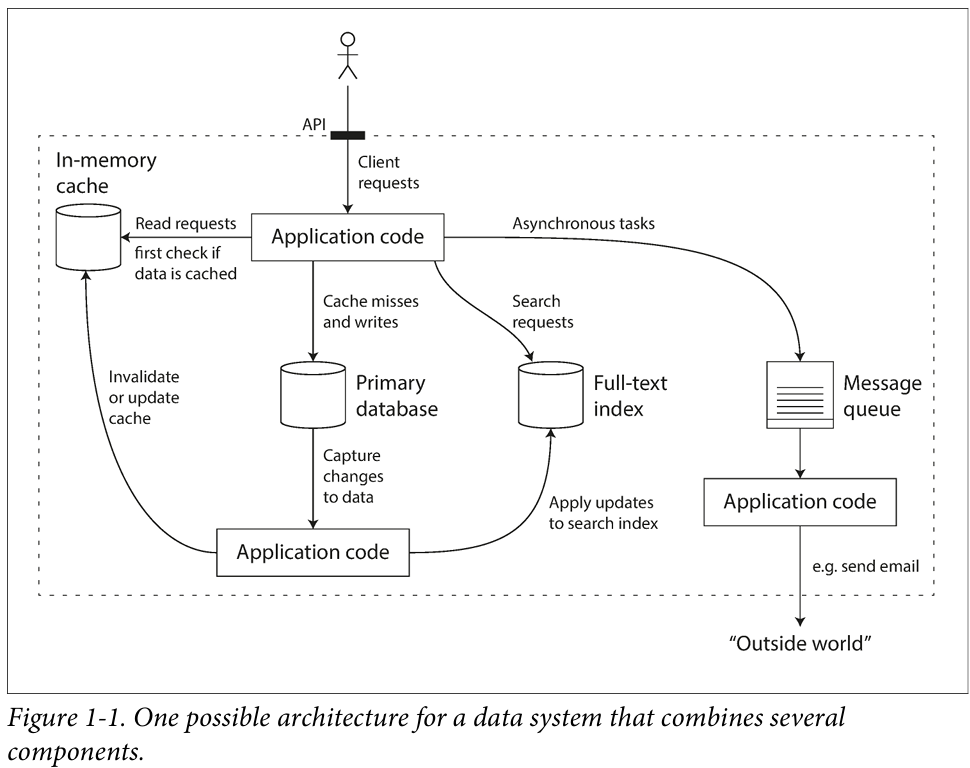
在上面例子中, 组合使用了多个组件来提供服务, 而对外提供服务的界面或者API会隐藏很多内部实现细节。
设计一个数据系统
设计数据系统或数据服务时, 一定会碰到很多棘手的问题。 例如, 当系统内出现了局 部失效时, 如何确保数据的正确性与完整性?当发生系统降级(degrade)时, 该如何 为客户提供一致的良好表现?负载增加时, 系统如何扩展?友好的服务API该如何设 计?
可靠性(Reliability)、可扩展性(Scalability)、可维护性(Maintainability)
这三个问题是对于绝大多数软件系统都应该考虑的。
可靠性
可靠性可以大致定义为:系统即使发生了某些错误,仍能继续正常工作。
可能出错的事情称为错误(faults)或故障, 系统可应对错误则称为容错(fault-tolerant)或者弹性(resilient)。
这里需要指明的是,容错的概念是相对的,应该是在特定的类型限定下,系统的容错才有意义。
对于具有可靠性的系统,我们通常采用以下方法对其进行测试:
在这种容错系统中,用于测试目的,可以故意提高故障发生概率,例如通过随机杀死某个进程, 来确保系统仍保持健壮。很多关键的bug实际上正是由于错误处理不当而造成的。通过这种故意引发故障的方式,来持续检验、测试系统的容错机制,增加对真实发生故障时应对的信心。Netflix的ChaosMonkey系统就是这种测试的典型例子。
我们通常将系统故障分为以下几类:
- 硬件故障:硬盘崩溃, 内存故障, 电网停电, 甚至有人误拔掉了网线。
- 解决措施:硬件冗余和软件冗余
- 软件错误:导致软件故障的bug通常会长时间处千引而不发的状态, 直到碰到特定的触发条件
- 解决措施:考虑细节,全面测试
- 人为失误
- 解决措施:以最小的方式来设计系统、分离易出错的接口、充分测试、提供快速恢复机制、设置监控子系统
可靠性为何如此重要? 可靠性关乎着商业软件的信誉和商业运作的效率。
可拓展性
可拓展性是指:系统在当前的负载下可以可靠运转,但它在日后并发用户数增多或处理数据量增大的情况下,是否还能保证可靠性。
负载和性能是描述可拓展性的两大关键因素。
如何描述负载?
负载通常是使用负载参数来描述。对于不同的体系结构的系统,负载参数的具体含义不同,它可能是Web服务器的每秒请求处理次数, 数据库中写入的比例,聊天室的同时活动用户数量,缓存命中率等。
我们以Twitter为例,使用其2012年11月发布的数据。Twitter的两个典型业务操作是:
- 发布tweet消息:用户可以快速推送新消息到所有的关注者,平均大约4.6k request/sec, 峰值约12k requests/sec。
- 主页时间线(Hometimeline)浏览:平均300k request/sec查看关注对象的最新消息。
庞大的用户量和复杂的关注列表,构造了该应用软件巨大的扇出(Fan-out)结构,针对这个难题,twitter提出了以下两种解决方案:
关系型数据模型:将发送的新推文插入到全局的tweet集合中。当用户查看时,首先根据关注者的id查询出所有新推文,再根据时间来排序,SQL语句类似下面这样:
SELECT tweets.*, users.* FROM tweets
JOIN users ON tweets.sender_id = users.id
JOIN follows ON follows.followee_id = users.id
WHERE follows.follower_id = current_user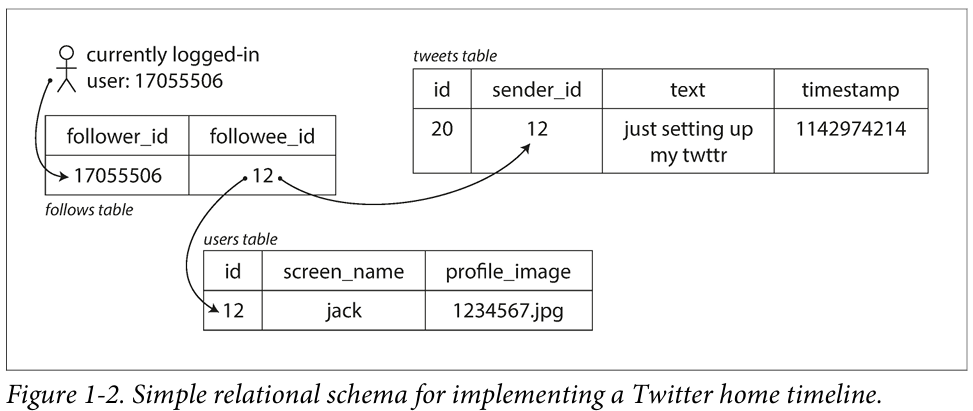
数据流水线:为每个用户设置一个类似于“收件箱”的邮箱,被关注者维护一个列表,每当发布新推文时,就向关注列表的所有用户发送数据。这样,当用户查看首页时,加载速度就会快很多。
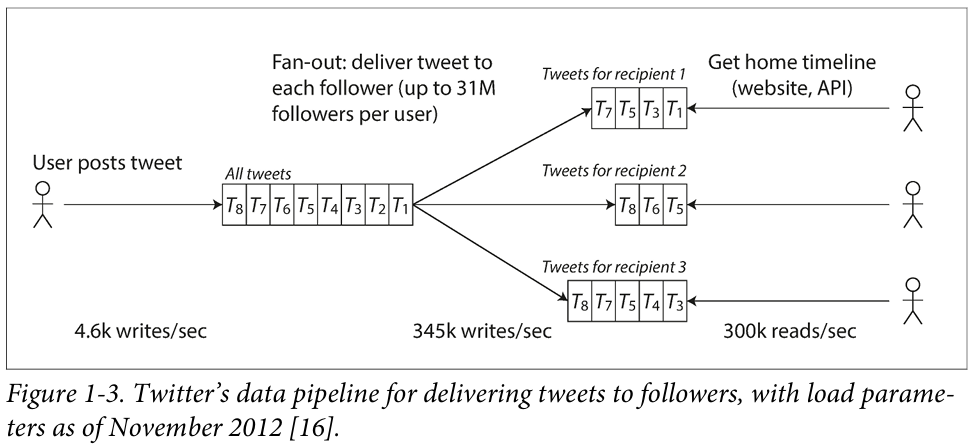
这两种方案各有优劣之处,在本案例中,负载参数是用户关注者的分布情况。
twitter最后采用的是将两种方案相结合,大多数用户的tweet在发布时继续以一对多写入时间线,但是少数具有超多关注者(例如那些名人)的用户除外,对这些用户采用类似方案1,其推文被单独提取,在读取时才和用户的时间线主表合并。这种混合方法能够提供始终如一的良好表现。
如何描述性能?
Comments NOTHING