测试链接:快速排序欢聚集团笔试题牛客网 (nowcoder.com)
经典随机快速排序
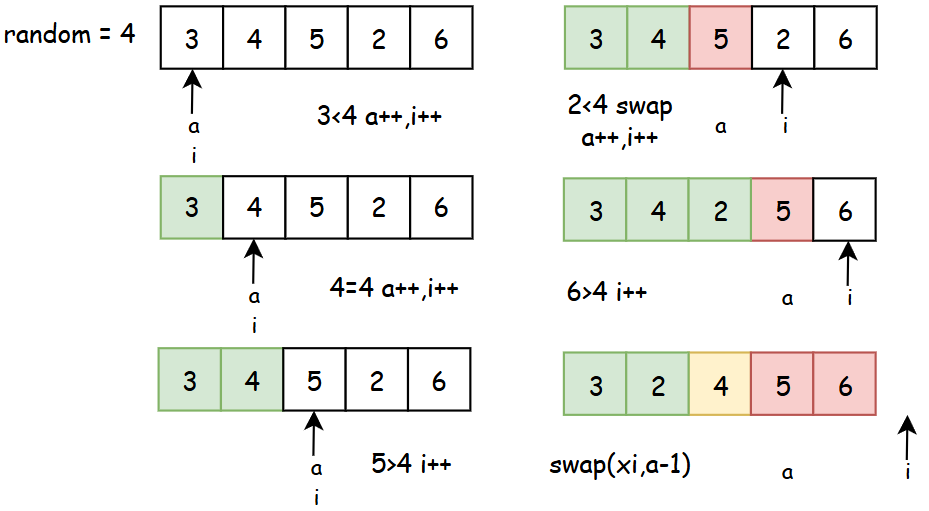
在给定数组中随机选一个数字x,将≤x的数字放在x左侧,且保证左区间最右侧数字为x,右侧区间所有数均>x。随后对左右区间递归执行此过程。
public static void quickSort1(int l, int r) {
// l == r,只有一个数
// l > r,范围不存在,不用管
if (l >= r) {
return;
}
// 随机这一下,常数时间比较大
// 但只有这一下随机,才能在概率上把快速排序的时间复杂度收敛到O(n * logn)
// l......r 随机选一个位置,x这个值,做划分
int x = arr[l + (int) (Math.random() * (r - l + 1))];
int mid = partition1(l, r, x);
quickSort1(l, mid - 1);
quickSort1(mid + 1, r);
}注意,partition函数返回的是随机元素的位置,不是随机元素的值,这是为了方便递归调用。
关于随机数生成方式的设计:(Math.random() * (r - l + 1))代表生成从0~(r - l + 1)范围上的随机数。这就保证了生成的数一定是该侧区间内的随机坐标.
partition1:此函数需要将≤x的数字放在x左侧,且保证左区间最右侧数字为x,右侧区间所有数均>x
public static int partition1(int l, int r, int x) {
// a : arr[l....a-1]范围是<=x的区域
// xi : 记录在<=x的区域上任何一个x的位置,哪一个都可以
int a = l, xi = 0;
for (int i = l; i <= r; i++) {
if (arr[i] <= x) {
swap(a, i);
if (arr[a] == x) {
xi = a;
}
a++;
}
}
swap(xi, a - 1);//保证左侧区间右边界数字为x
return a - 1;
}a是标记指针,标记越界位置;
i是探路指针,不断右移,扩大左侧区间(l,a-1)位置(a++,i++),或扩大右侧区间(a-r)位置(i++).
针对partition过程的优化(荷兰国旗问题)
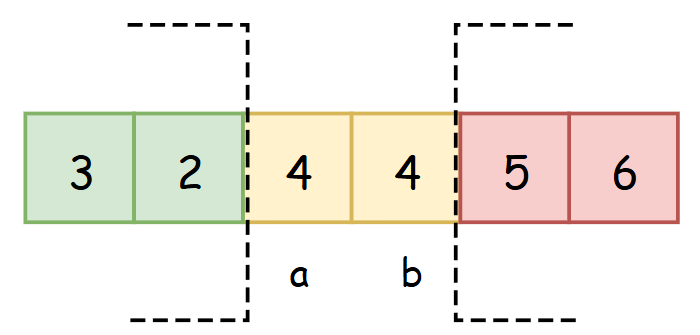
观察上面的过程,其中一次划分的结果是随机数被固定在左数组的右边界,但左侧数组中还可能存在其他等于x的数,所以我们可以将原本的左右区间变更为左中右区间,将所有等于随机数的数字都放在中区间内.即新增一个分支:
- i < random : swap(a,i),a++,i++
- i = random : i++
- i > random swap(b,i),b--
针对第三分支中的i,这里为什么不像第一分支一样递增呢?
这是因为原本b所指元素并未与random比较,需要在下一轮中与random比较.
public static void partition2(int l, int r, int x) {
first = l;//图中a
last = r;//图中b
int i = l;
while (i <= last) {
if (arr[i] == x) {
i++;
} else if (arr[i] < x) {
swap(first++, i++);
} else {
swap(i, last--);
}
}
}终止条件是i移动到b的右侧.
针对此过程的优化也是著名的荷兰国旗问题.
public static void quickSort2(int l, int r) {
if (l >= r) {
return;
}
int x = arr[l + (int) (Math.random() * (r - l + 1))];
partition2(l, r, x);
// 为了防止底层的递归过程覆盖全局变量
// 这里用临时变量记录first、last
int left = first;
int right = last;
quickSort2(l, left - 1);
quickSort2(right + 1, r);
}时间复杂度分析
当随机行为作为算法的重要枢纽的情况下,估算时间复杂度不能以最差情况来估计,应以期望来估计.
设想利用随机函数生成一个数组,假设0位置上已经生成了一个随机数3,接下来生成1位置上的数,由于随机函数的不可控性,1位置上若想得到不是3的数字,需要的次数可能是无穷,时间复杂度达到了O(正无穷),失效.
关于为什么要使用随机函数来确定划分位置,而不是指定一个位置的数来做划分位置(比如最右侧数字)?
指定某一位置的数,可能造成的是该数的值实际上在整个数组中属于比较小或比较大(极端)的情况,这样一来,每次划分后需要比较的数字的量就可能比较大.
结论: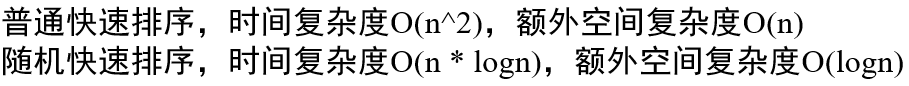
Comments NOTHING